
Une grande quantité de documents est traitée tous les jours dans les administrations. Sans surprise, beaucoup de use cases qui nous sont présentés relèvent du traitement automatique de documents.
L’un des besoins exprimé par les clients est de disposer d’un système de filtrage de documents dans le cadre de l’analyse de dossiers. L’implémentation d’un système de filtrage s’appuie sur plusieurs éléments :
- La recherche sur les métadonnées (information structurée). Les documents sont associés à des métadonnées définis manuellement par un agent. Celles-ci peuvent être enrichies automatiquement grâce à des techniques telles que l’extraction d’entités (NER) ou le topic modeling qui consiste à extraire les principaux thèmes traités dans les documents.
- La recherche sur le contenu (information non-structurée). Typiquement, la recherche se fait à partir d’une requête introduite par un utilisateur sur des contenus indexés. Un cas particulier de la recherche sur le contenu est de retrouver des documents dont le contenu est similaire. Ceci permet de retrouver et de consulter les traitements de dossiers portant sur des sujets similaires.
C’est ce dernier scénario que nous allons aborder ci-dessous en présentant une expérience que nous avons réalisée sur le calcul de similarité entre deux textes.
Il y a deux façons d’aborder la similarité entre textes :
- La similarité lexicale. Les textes sont considérés comme un ensemble de mots, la similarité entre deux textes est caractérisée par le degré de recouvrement entre les ensembles de mots relatifs aux textes considérés. La similarité lexicale présente cependant quelques inconvénients : l’ordre des mots dans la phrase ainsi que les relations entre les mots ne sont pas pris en compte. Deux documents peuvent avoir peu de recouvrements entre leurs vocabulaires et parler de sujets similaires car le langage naturelle comprend de nombreuses façons d’exprimer une même idée.
- La similarité sémantique. Cette méthode est une extension de la précédente qui intègre la sémantique des mots notamment via la vectorisation de texte avec des techniques comme le word embeddings ou l’utilisation de transformers tels que BERT.
L’expérience s’est faite en trois étapes : le prétraitement du contenu, la représentation numérique de texte (vectorisation) et enfin le calcul de similarité.
Le prétraitement des textes à comparer
Tout traitement automatique de textes (ou corpus) commence toujours par une étape de « nettoyage ». Cela implique la normalisation de texte pour enlever les caractères spéciaux, la division du texte en plus petites unités (typiquement des mots) , la conversion des mots en minuscule et/ou en lemme, la suppression de la ponctuation, des mots les plus fréquents, etc. Le traitement à appliquer sera déterminé par le problème que l’on veut résoudre et la qualité du corpus.

Représentation vectorielle des textes
La plupart des algorithmes utilisent des données numériques comme input et le texte dans sa forme brute ne peut être utilisé tel quel. Il faut donc passer par une étape de transformation de données textuelles en données numériques représentées sous forme de vecteurs sur lesquelles on peut appliquer des opérations vectorielles. Ces vecteurs doivent être tels que les propriétés linguistiques du texte soient conservées.
Nous allons aborder ici les techniques les plus courantes de représentation vectorielle des textes, le choix de l’une ou de l’autre de ces techniques affecte le calcul de similarité comme nous le verrons dans l’expérience décrite ci-dessous.
Bag of Words (collection de mots)
Chaque document est représenté par un vecteur de taille fixe égal au nombre de mots du vocabulaire du corpus V (ensemble de mots présents dans le corpus) dont chaque élément représente le nombre d’occurrence d’un mot mi dans le document. Les mots sont considérés individuellement et l’ordre dans lesquelles ils apparaissent dans une phrase n’est pas pris en compte.
Term Frequency – Inverse Document Frequency (TF-IDF)
Le TF-IDF est une variation du BoW. Dans la méthode précédente les mots sont considérés de même importance dans chaque document. Cependant les mots récurrents dans un document d et rares dans le reste du corpus sont plus informatifs sur ce document que les mots apparaissants de façon équivalente dans tous les documents du corpus. La méthode TF-IDF permet donc d’ajuster le poids d’un mot dans un document en fonction de sa fréquence dans le document et dans le reste corpus.
La valeur de chaque élément (t) du vecteur représentant le document (d) est déterminée par la formule suivante :

Les représentations BoW et TF-IDF produisent des vecteurs larges et clairsemés (contenant beaucoup de 0) et capturent mal la sémantique des mots. Une des solutions possible à ce problème de vecteurs larges est la réduction de dimension avec des méthodes telles que l’analyse sémantique latente (LSA). Cet algorithme vise à réduire le texte à ses concepts principaux.
Word embeddings (Word2Vec, Glove, fastText)
Les words embeddings tentent de corriger les inconvénients des méthodes décrites ci-dessous en produisant pour chaque mot un vecteur compact et dense tel que des mots ayant une signification similaire sont représentés par des vecteurs proches dans l’espace vectoriel. Chaque élément du vecteur représente un aspect de la signification du mot. Les modèles type « word vector » les plus populaires sont Word2Vec, Glove et fastText.
La représentation vectorielle du document tout entier peut-être calculée en prenant la moyenne des vecteurs de chaque terme présent dans le documents.
Transformers
Les transformers sont les modèles de représentation textuelle les plus avancés dans le domaine du NLP. Ils prennent en compte le fait qu’un mot, selon le contexte, aura un sens différent. Dans ce modèle, le mot est représenté par des vecteurs différents selon le contexte (voir plus de détails sur les transformes dans ce blog).
Mesure de similarité
Similarité Jaccard (similarité syntaxique)
C’est la forme la plus basique de calcul de similarité entre deux textes car elle ne nécessite pas d’avoir une représentation numérique des textes. L’indice de Jaccard est mesuré en divisant le nombre de mots partagés par les deux textes par le nombre total de mots. Cependant, plus les documents sont longs plus le nombre de mots partagés sera élevé sans pour autant que ces documents soient similaires.
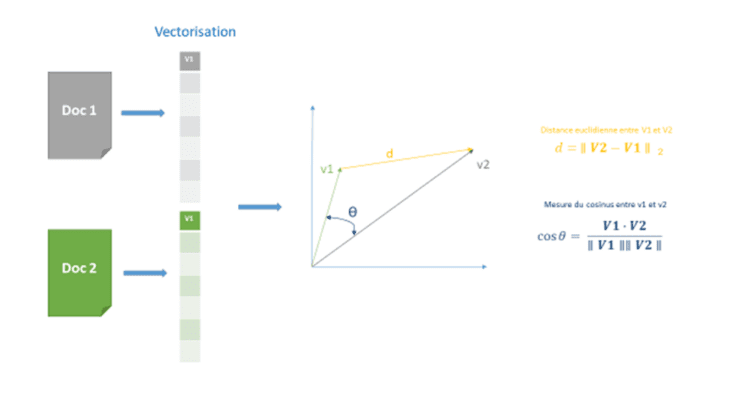
Distance euclidienne
C’est la distance entre deux vecteurs représentants les documents. Cette mesure est utilisée spécifiquement par l’algorithme K-means.
Similarité cosinus
A la différence de la distance euclidienne, c’est l’angle entre les vecteurs et non la taille des vecteurs qui est pris en compte, ce qui a pour effet de réduire l’impact de la taille des documents sur le calcul de similarité. Cette méthode est la plus couramment utilisée car simple et efficace d’un point de vue computationnel.
Comparaison de plusieurs approches de calcul de similarité
Le but de l’exercice consiste à retrouver dans un corpus de 400 documents, les 5 documents les plus similaires à un document donné qui constitue notre requête. Des utilisateurs experts ont classé les documents de test en 8 catégories et 36 sous-catégories. On considère que des documents sont similaires s’ils appartiennent à la même catégorie et sous-catégorie que le document requête.
Nous avons essayé plusieurs combinaisons de représentation vectorielle et mesure de similarité cependant c’est l’étape de vectorisation de texte qui est déterminante pour l’efficacité de la recherche de documents similaires. Nous nous limitons donc à comparer les différentes représentations vectorielles en utilisant la similarité cosinus comme mesure de similarité avec l’algorithme kNN pour retrouver les 5 documents les plus proches du document requête.
Les différentes représentations vectorielles implémentées sont les suivantes:
- TF-IDF
- TF-IDF + LSA
- Word embeddings – fastText (source: Word vectors for 157 languages · fastText)
- Word embeddings – fastText amélioré (fine-tuned) en intégrant des données du domaine
- Word embeddings – Word2vec entrainé sur des données du domaine uniquement
Première évaluation des différents word embeddings
Pour nos premiers tests, nous utilisons des word embeddings libre d’accès et entrainés sur des millions de documents. Néanmoins, les textes utilisés pour entrainer ces modèles sont éloignés de notre domaine et les représentations produites pour des textes contenant un vocabulaire propre à la sécurité sociale sont moins précises.
En recherchant les mots les plus similaires (proches dans l’espace vectorielle) aux mots « cotisation » et « Dmfa » on obtient les résultats suivants :

Ces résultats illustrent les spécificités de chacun des modèles Word2Vec et fastText : le modèle fastText capture les différentes formes morphologiques des mots tandis que le modèle Word2Vec capture les relations entre les mots apparaissant dans un même contexte. Autre point d’attention, pour le mot « cotisation » les mots similaires donnés par le modèle Word2Vec tels que rafp et csg-crds sont parfaitement logiques dans un contexte français mais ne sont pas d’utilité dans le contexte de la sécurité sociale belge.
Avec la librairie python Gensim, il est possible d’entrainer ou d’affiner des modèles de word embeddings et nous disposons pour cela d’un corpus très limité de 3500 documents. Nous utilisons ce corpus pour affiner le modèle fastText précédemment décrit et pour entrainer « from scratch » un modèle word2vec ce qui donne les résultats suivants.

Le modèle fastText s’est amélioré, le terme « dmfa » a une représentation vectorielle cependant les termes similaires à ce terme se réfèrent pour la plupart à des institutions de sécurité sociale étrangères. Quant au modèle Word2Vec, bien qu’ayant été entrainé avec très peu de textes, on constate qu’il donne déjà des résultats satisfaisants.
Évaluation des différentes représentations de textes sur les documents de test
Les différentes représentations vectorielles implémentées sont les suivantes:
- TF-IDF
- TF-IDF + LSA
- Word embeddings – fastText (source: Word vectors for 157 languages · fastText)
- Word embeddings – fastText amélioré (fine-tuned) en intégrant des données propres à notre domaine
- Word embeddings – Word2Vec entrainé avec des données du domaine uniquement
Pour chacune d’elles, on recherche les 5 documents les plus similaires d’un document requête et on calcule la proportion de documents similaires qui appartiennent à la même catégorie et la même sous-catégorie que ce document requête.

Les modèles TF-IDF et Word2Vec sont ceux qui donnent les meilleurs résultats. Les documents retrouvés par les deux modèles appartiennent tous à la bonne catégorie et sous-catégorie cependant seuls 2 documents sur 5 sont communs aux deux sets de résultats (TF-IDF et Word2Vec). En analysant de près les résultats, on constate que le modèle Word2Vec a privilégié des documents se référant à des entreprises de restauration. Le document requête concerne lui aussi une entreprise de restauration.
Conclusion
Nous avons vu comment déterminer si deux textes sont similaires. On constate que le choix du type de représentation vectorielle est important pour cette tâche. Sans surprise les modèles qui intègrent la sémantique d’un mot donnent, dans notre use case, des résultats plus pertinents. Ils existent des représentations type word embedding prêtes à l’emploi (Word2Vec, fastText, GloVe). Cependant si on traite des textes qui relèvent d’un domaine ayant un vocabulaire spécifique, il est préférable d’entrainer son propre word embedding « from scratch ».
Ce post est une contribution individuelle de Katy Fokou, spécialisée en intelligence artificielle chez Smals Researc. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals. Cela t’intéresse de travailler chez Smals ? Jette un coup d’œil à leurs offres d’emploi actuelles.