
L’évolution phénoménale des techniques d’apprentissage automatique (« machine learning (ML) ») et, plus généralement « d’intelligence » artificielle (IA), semble avoir atteint son acmé au cours des dernières années avec l’arrivée en force de l’IA générative (« Generative AI (GenAI) ») et l’emblématique « ChatGPT1. » Nonobstant les nombreuses limites de ces technologies et les risques qu’elles posent, il existe des applications positives dans de nombreux domaines (par ex. moteurs de recherche, traduction automatique, annotation automatique d’images, etc.), et l’on peut se demander quel pourrait-être l’apport de ces technologies en cybersécurité.
En fait, les experts en cybersécurité n’ont pas attendu la venue de l’IA générative pour utiliser des techniques d’IA. Mais dans le domaine de la cybersécurité, comme c’est souvent le cas avec d’autres technologies, l’application de l’IA est souvent considérée comme une arme à double tranchant dans la mesure où elle peut être utilisée pour l’attaque aussi bien que pour la défense : d’un côté l’IA permet de mettre au point des attaques de plus en plus sophistiquées, et de l’autre, d’apporter des réponses plus efficaces aux attaques, comme l’amélioration de la détection de menaces et d’anomalies et le soutien opérationnel des analystes en sécurité.
L’introduction d’attaques informatiques aidées par l’IA pourrait même ouvrir, selon Renault et al., une nouvelle ère dans la course sécuritaire avec des transformations connues et inconnues des vecteurs d’attaques. Mais bien qu’il ne fasse aucun doute que les adversaires utiliseront ou ont commencé à utiliser l’IA générative, afin de créer des courriels d’hameçonnage plus réalistes et efficaces ou encore pour se faire passer pour d’autres utilisateurs, il n’est pas du tout évident qu’ils pourront utiliser l’IA générative pour lancer des attaques plus sophistiquées ou même créer de nouvelles classes d’attaques.
Quoi qu’il en soit, malgré des améliorations possibles, la prolifération d’annonces concernant l’IA dans le domaine de la cybersécurité (par exemple Crowdstrike, Google, Microsoft, et SentinelOne ont récemment annoncé l’emploi d’IA générative dans leurs produits de sécurité) pourrait conduire à de fortes déceptions.
Ces déceptions pourraient être accentuées par le fait que la performance ou la précision des systèmes de cybersécurité n’est pas normalisée dans son ensemble, ce qui rend difficile la comparaison de différents systèmes et soulève des questions comme : « Quelle est la meilleure façon d’évaluer, de configurer ou de comparer différents systèmes de cybersécurité ? » ou « Disposons-nous d’une méthodologie universelle pour évaluer la robustesse et la performance dans tous les scénarios ou dans des scénarios différents ? » ou encore « Un système performant sur les données du fabriquant, le sera-t-il autant sur mes propres données ? » Plus prosaïquement, que se cache-t-il réellement derrière le terme d’intelligence artificielle, lorsqu’il est adossé à des produits de cybersécurité ?
La réponse à cette dernière question est loin d’être évidente étant donné le nombre important de techniques très différentes entrant dans le domaine de l’IA. Dans la suite de cet article nous décrivons brièvement ce qui se cache derrière le terme « d’intelligence artificielle » en décrivant quelques techniques de base utilisées en cybersécurité. Dans les articles suivants nous passerons en revue l’utilisation possible de ces techniques pour l’attaque comme pour la défense dans le contexte de la cybersécurité.
Principales techniques d’apprentissage automatique
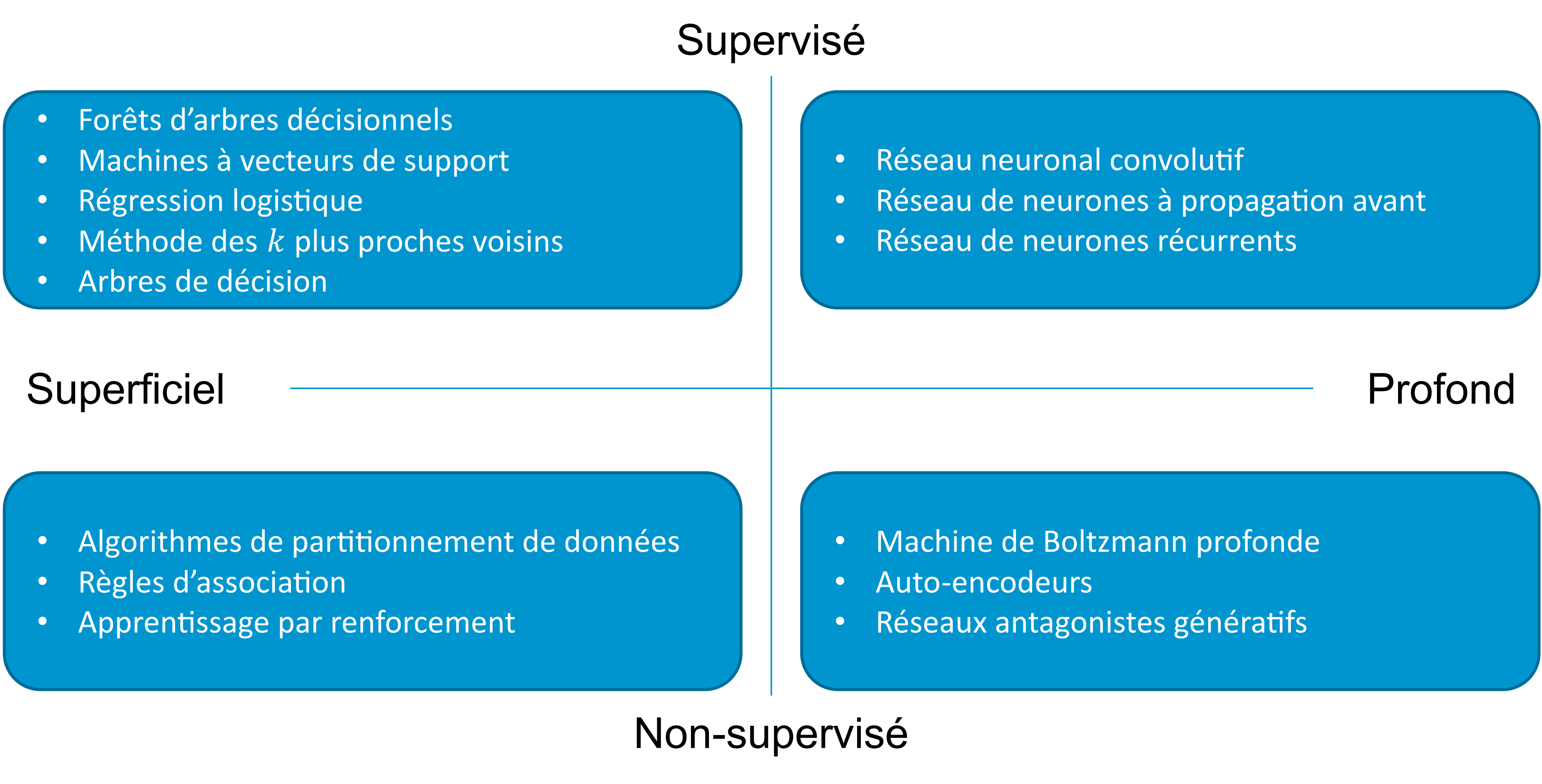
Au cours de la dernière décennie, l’apprentissage automatique a permis des avancées importantes dans différents domaines, d’abord avec des modèles dit supervisés (on indique à la machine la classe des éléments à apprendre, par exemple telle transaction est frauduleuse ou bénigne), puis non-supervisé (la machine doit découvrir elle-même les différentes classes en fonction des données), l’apprentissage par renforcement (la machine reçoit une forme de récompense lorsqu’elle classifie correctement des informations). L’image ci-dessous montre les principaux algorithmes d’apprentissage automatique utilisés en cybersécurité.

Apprentissage supervisé
{kind=link}
Les modèles d’apprentissage supervisé sont formés à partir de données étiquetées, c’est-à-dire qu’une catégorie est fournie pour chaque élément du jeu de données d’apprentissage. Une catégorie peut être binaire (par ex. « attaque » ou « bénin ») ou multiple (par ex. type d’attaque). Cela suppose en amont, un travail manuel coûteux de catégorisation des données. Pour un système de cybersécurité cela implique par exemple que les analystes catégorisent chacune des données qu’ils ont analysées, avec la difficulté supplémentaire qu’il y a en général peu d’exemples d’attaques par rapport aux autres exemples.
L’apprentissage consiste alors à découvrir, à partir des données étiquetées, les caractéristiques liées à chaque catégorie et à construire un modèle pouvant établir avec une certaine probabilité à quelle catégorie appartient un nouvel élément jamais vu lors de l’apprentissage.
Cependant ces systèmes supervisés ne peuvent pas être utilisés pour détecter des types d’attaques qui ne leur sont pas déjà connus. De plus, bien que l’apprentissage supervisé fonctionne particulièrement bien pour la reconnaissance d’objets dans les images, la détection de menaces de cybersécurité présente des difficultés particulières. En effet, comme le font remarquer Apruzzese et al., un échantillon étiqueté comme malicieux dans un certain contexte peut être bénin dans un autre, un échantillon peut être créé spécialement pour ressembler à un échantillon bénin, ou encore un échantillon étiqueté bénin aujourd’hui, peut s’avérer dangereux demain.
Les exemples d’algorithmes d’apprentissage supervisé incluent : les arbres de décision (« decision trees (DT) »), les forêts d’arbres décisionnels (« random forests (RF) »), la classification naïve bayésienne, les réseaux de neurones artificiels (« neural networks (NN) »), les machines à vecteurs de support (« support vector machines (SVM) »), etc.
Apprentissage non-supervisé
Les algorithmes d’apprentissage non-supervisés quant à eux, apprennent les informations et créent des groupes sur la base de l’ensemble des données d’apprentissage, sans connaître la catégorie de chaque donnée. La différence entre l’apprentissage supervisé et l’apprentissage non-supervisé est donc que ce dernier n’a pas d’étiquettes de catégories dans ses données d’apprentissage.
Des exemples d’algorithmes d’apprentissage non-supervisés sont ceux qui tentent de grouper ensemble les échantillons d’un même type, comme le partitionnement en k-moyennes (« k-means ») et la méthode des k plus proches voisins (« k-nearest neighbours (k-NN) »). En dehors du regroupement, l’utilisation plus récente d’auto-encodeurs est une technique assez populaire pour la détection d’anomalies et en particulier d’intrusions.
Un auto-encodeur est composé d’une couche d’entrée (codeur), de plusieurs couches cachées et d’une couche de sortie (décodeur). L’objectif est d’apprendre une représentation comprimée de certaines données d’entrée. Le codeur est utilisé pour mettre en correspondance les données d’entrée dans une représentation cachée, le décodeur est destiné à reconstruire les données d’entrée à partir d’une telle représentation. Un encodeur peut être entraîné avec des données bénignes afin d’apprendre une représentation normale du trafic sur un réseau. Ensuite, pendant la phase de détection, un échantillon est considéré comme anormal si, après son encodage, l’erreur de reconstruction est supérieure à un certain niveau.
Apprentissage semi-supervisé
L’apprentissage semi-supervisé est basé à la fois sur des données étiquetées et des données non étiquetées. Il permet de fournir des classificateurs efficaces qui nécessitent de petites quantités de données étiquetées en exploitant les informations obtenues à partir de grands ensembles de données non étiquetées. De nombreux chercheurs ont constaté que les données non étiquetées, lorsqu’elles sont utilisées en conjonction avec une petite quantité de données étiquetées, peuvent améliorer considérablement la précision de l’apprentissage par rapport à l’apprentissage non supervisé, mais sans le temps et les coûts nécessaires à l’apprentissage supervisé.
Dans l’apprentissage actif par exemple, un algorithme de classification initialement entraîné sur un petit ensemble de données étiquetées (par ex. « normal, » « rootkit, » « teardrop ») peut être utilisé pour analyser un grand ensemble de données brutes, puis « suggérer » les échantillons les plus avantageux à étiqueter. Ces échantillons sont sélectionnés grâce à un algorithme non supervisé de détection d’anomalies. Un expert est ensuite consulté pour étiqueter les échantillons présentés et le modèle est mis à jour.
Plusieurs travaux ont proposé des solutions d’apprentissage semi-supervisé dans différents domaines de cybersécurité, que ce soit la détection de logiciels malveillants (par ex. [12]) ou la détection d’intrusions. Beaucoup de méthodes s’inspirent de la méthode populaire de co-apprentissage proposée à la fin des années 1990.
Apprentissage par renforcement
L’apprentissage par renforcement (« reinforcement learning (RL) »), est basé sur l’essai et l’erreur : un agent autonome apprend à prendre des décisions dans un environnement donné. L’environnement offre une récompense ou pas à l’agent après chaque décisions prise. Les données d’apprentissage dans l’apprentissage par renforcement sont un mélange d’approches supervisées et non-supervisées : au lieu de fournir des données avec l’étiquette correcte, l’algorithme explore les actions jusqu’à ce qu’elles soient correctes.
Malgré l’avantage de l’apprentissage par renforcement qui sait s’adapter à des changements dans l’environnement, il reste une difficulté limitant son utilisation dans la cybersécurité : la définition de la fonction de récompense en particulier dans le domaine de la détection d’intrusions.
Apprentissage automatique fédéré
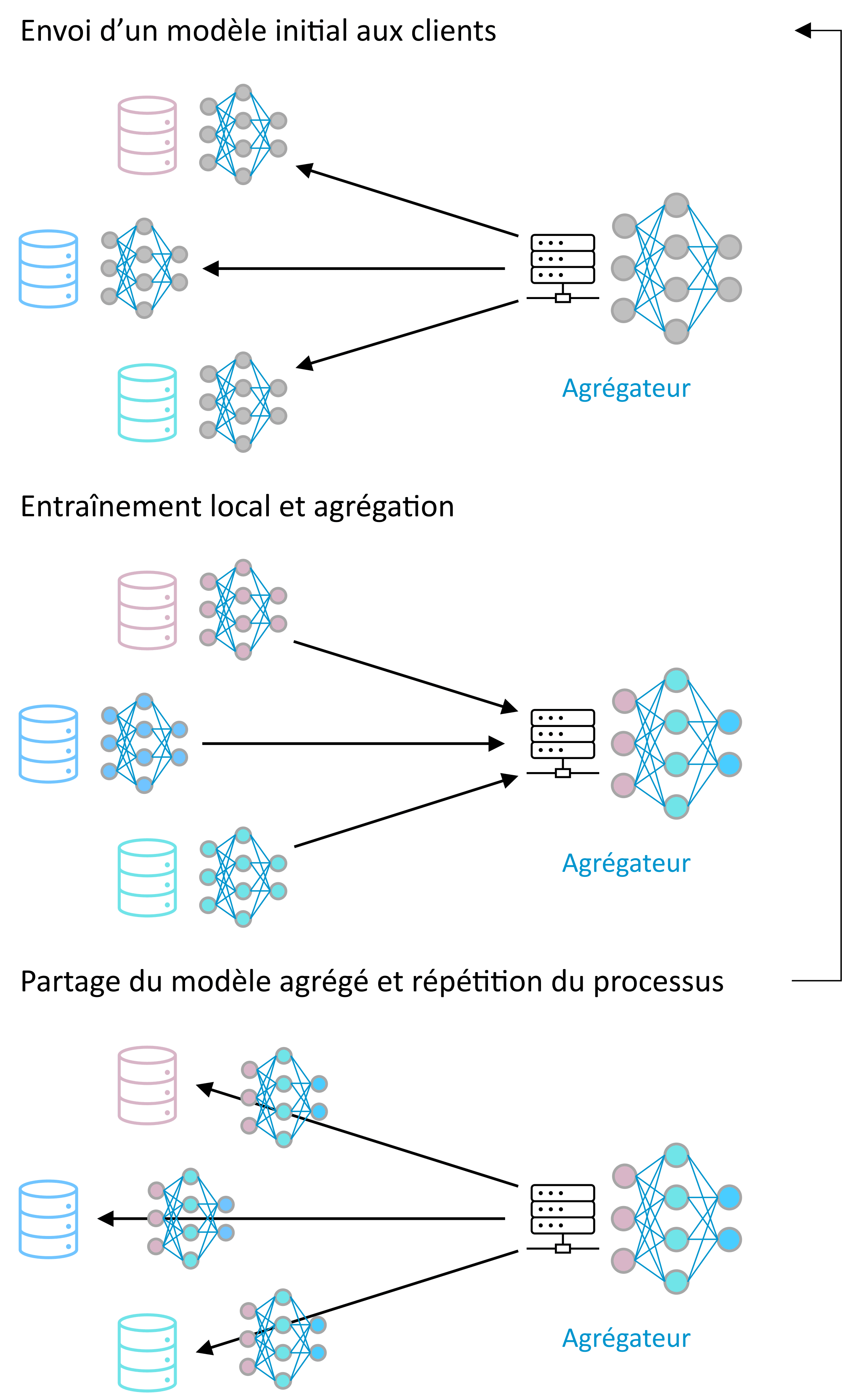
Introduit par McMahan et al., l’apprentissage automatique fédéré (« federated learning ») est une manière distribuée et collaborative de faire de l’apprentissage automatique. Les machines participant à l’apprentissage ne sont pas obligées de partager leurs données et se contentent d’envoyer des modèles appris sur leurs données afin de contribuer à un modèle global qui est le résultat de la combinaison de l’ensemble des modèles locaux9.
{kind=link}
Figure 2 – Exemple d’apprentissage fédéré centralisé : un serveur central orchestre l’apprentissage, permettant un protocole relativement simple. Dans le cas non-centralisé, les participants s’envoient des modèles partiels en pair-à-pair.
D’après Hernández-Ramos et al. l’apprentissage fédéré pourrait jouer un rôle important dans le domaine de la cybersécurité car il pourrait permettre à des organisations distinctes de partager des informations sur les menaces et les attaques de sécurité sans avoir besoin de partager leurs données réelles et potentiellement sensibles. Dans leur analyse, les auteurs soulignent que l’utilisation de l’apprentissage automatique fédéré dans le domaine de la détection d’intrusions a proliféré au cours des dernières années. Malgré leur coût et leurs limites, les méthodes fédérées supervisées restent les plus couramment étudiées par rapport aux méthodes fédérées non-supervisées.
Modèles massifs de langage
Les modèles massifs de langage (« Large Language Models (LLM) ») sont obtenus par un apprentissage non-supervisé de réseaux de neurones profonds entraînés sur de très grandes quantités de textes non étiquetés. On trouve parmi eux les transformeurs, génératifs pré-entrainés (« generative pre-trained transformers (GPT) ») dont la fonction principale est de prédire de manière statistique le mot suivant dans un passage de texte. Une description plus détaillée de ces modèles peut être trouvée dans.
Les applications de ces modèles à la cybersécurité sont encore limitées car peu d’entre elles utilisent du texte et des données dans un langage naturel. Cependant, un aspect intriguant de ces modèles massifs de langage est l’hypothèse contestée selon laquelle ils exhiberaient des capacités émergentes, qui « ne sont pas présentes dans les modèles à plus petite échelle, mais qui sont présentes dans les modèles à grande échelle ». On peut donc se poser la question si ces capacités émergentes pourraient inclure la cybersécurité.
Une approche permettant de bénéficier des architectures des LLM est d’utiliser des transformeurs et d’autres aspects architecturaux des LLM, et de pré-entraîner le modèle sur des données de sécurité. Bien que les transformeurs soient surtout connus pour leur résultat dans le traitement des langages naturels, ils peuvent également être considérés pour la détection d’intrusions.
Étant donné les avancées récentes des modèles génératifs, il est très probable qu’ils seront beaucoup étudiés dans les années qui viennent pour le développement de détection d’intrusions.
Conclusions
L’intérêt pour les techniques d’IA dans le domaine de la sécurité est évident, ne serait-ce qu’au vu du nombre important de publications, des articles de revue de littérature sur le sujet et des produits de cybersécurité se targuant de leur emploi.
Cependant, s’il ne fait aucun doute que l’IA est utile pour analyser des données existantes, les résultats donnés sont, comme nous l’avons vu, par construction, basés sur les données déjà observées. Par conséquent, même si les progrès impressionnants de l’IA peuvent le laisser imaginer, il reste encore à prouver que l’IA a des capacités créatrices suffisantes lui permettant de détecter des nouveaux vecteurs d’attaques sans requérir à l’expertise et l’intuition humaine. De plus, l’évaluation d’un risque dépend de nombreux facteurs parfois difficilement quantifiables comme le contexte géopolitique ou socio-économique.
L’IA doit donc être considérée comme une étape dans l’évolution de la sécurité, plutôt que comme une révolution complète. Comme nous le verrons dans un prochain article, elle joue un rôle dans l’amélioration des pratiques de sécurité, mais ne doit pas remplacer entièrement l’intervention humaine et la prise de décision.
Ce post est une contribution individuelle de Fabien A. P. Petitcolas, spécialisé en sécurité informatique chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.Cela t’intéresse de travailler chez Smals ? Jette un coup d’œil à leurs offres d’emploi actuelles.