
Vous aimez ChatGPT mais préférez ne pas envoyer de données à OpenAI ? Utilisez la version locale de ChatGPT. Nous vous expliquons comment démarrer.
ChatGPT contient un LLM (Large Language Model) en arrière-plan. Celui-ci fonctionne sur les serveurs d’OpenAI, où une puissance de calcul considérable assure une réponse immédiate à vos questions. L’inconvénient est que vous utilisez un service cloud. Vos questions (et réponses) ne sont pas privées. Il est préférable de ne pas transmettre des données d’entreprise sensibles pour en tirer des conclusions.
Pour utiliser ChatGPT tout de même, vous pouvez désormais utiliser une version téléchargeable open source. Télécharger et utiliser rapidement ? Malheureusement, ce n’est pas si simple. L’utilisation locale d’un LLM nécessite des outils spécifiques.
Pour ce tutoriel, nous utilisons Ollama, l’une des options les plus conviviales du marché. Les captures d’écran que vous voyez ici proviennent d’un PC Windows, mais les étapes sont identiques pour Mac.
-
Étape 1 : Déterminer la puissance de votre GPU
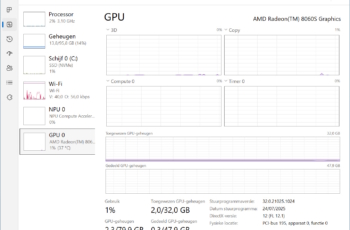 Avant de tester des modèles avec enthousiasme, vous devez d’abord vérifier si votre PC est compatible. Faire fonctionner un LLM localement nécessite beaucoup de puissance de calcul et de VRAM. Ce dernier est la quantité de mémoire de votre carte graphique (GPU). Appuyez simultanément sur Ctrl+Shift+Esc sur un PC Windows et sélectionnez GPU à gauche. Sous Mémoire GPU au centre en bas, vous verrez combien votre GPU utilise actuellement de sa mémoire et combien il en dispose au total.
Avant de tester des modèles avec enthousiasme, vous devez d’abord vérifier si votre PC est compatible. Faire fonctionner un LLM localement nécessite beaucoup de puissance de calcul et de VRAM. Ce dernier est la quantité de mémoire de votre carte graphique (GPU). Appuyez simultanément sur Ctrl+Shift+Esc sur un PC Windows et sélectionnez GPU à gauche. Sous Mémoire GPU au centre en bas, vous verrez combien votre GPU utilise actuellement de sa mémoire et combien il en dispose au total. -
Étape 2 : Quels modèles pouvez-vous exécuter ?
Plus la mémoire GPU est élevée, mieux c’est. Aujourd’hui, il faut au minimum 16 Go pour faire fonctionner les modèles de base correctement. Vous trouverez ici une vue d’ensemble complète de tous les LLM compatibles avec ce tutoriel.
Chaque modèle possède différentes variantes, chacune avec un certain nombre de milliards de paramètres. Les petits modèles se reconnaissent aux 1b ou 0,6b ou 4b : respectivement 1, 0,6 et 4 milliards de paramètres. Vous pouvez les exécuter facilement avec un GPU disposant de 16 Go de mémoire.
 Plus il y a de paramètres, meilleur est le résultat. La version open source de ChatGPT que vous pouvez exécuter localement possède respectivement 20 et 120 milliards de paramètres et porte les labels 20b et 120b.
Plus il y a de paramètres, meilleur est le résultat. La version open source de ChatGPT que vous pouvez exécuter localement possède respectivement 20 et 120 milliards de paramètres et porte les labels 20b et 120b.OpenAI indique que la version 20b de ChatGPT nécessite au minimum 16 Go. La version 120b nécessite un GPU avec 80 Go. Cette dernière configuration est assez exotique et ne se trouve que dans les puces Apple M, les GPU Nvidia H100 ou un AMD Ryzen AI Max+ APU.
Une règle empirique pratique : le nombre de paramètres en milliards correspond approximativement à la quantité de mémoire dont votre GPU a besoin pour fonctionner. Vous avez peu de mémoire GPU ? Expérimentez avec des petits modèles. Vous voulez exécuter ChatGPT localement ? Alors il vous faut au minimum 16 Go.
-
Étape 3 : Installer Ollama
Avant de commencer, téléchargez la version appropriée via ce lien : Windows, Linux ou macOS. Nous continuons ce guide avec la version Windows. Cliquez sur le bouton Download for Windows. Le fichier d’installation est très simple : cliquez sur Installer. Vous êtes maintenant prêt à tester les LLM sur votre PC.
-
Étape 4 : Télécharger les modèles de langage
Avant de pouvoir utiliser ChatGPT, nous devons d’abord installer le LLM localement. Démarrez Ollama et sélectionnez gpt-oss:20b à droite. Tapez Bonjour dans la fenêtre de message pour lancer le téléchargement. Au moment de la rédaction, le modèle fait 12,8 Go. Une fois le téléchargement terminé, ChatGPT formulera une réponse.
Vous pouvez répéter la même opération pour d’autres modèles dans le menu. L’interface graphique d’Ollama prend actuellement en charge ChatGPT, Deepseek, Gemma et Qwen. D’autres modèles peuvent être appelés via le Terminal Windows, mais nous n’aborderons pas cela dans ce tutoriel. Nous nous concentrons maintenant sur ChatGPT et l’interface conviviale d’Ollama qui a été construite pour cela.
-
Étape 5 : Longue attente pour les réponses ?
Un LLM est, comme son nom l’indique, un grand modèle de langage avec des milliards de paramètres. Selon la puissance de votre GPU et la quantité de mémoire dont il dispose, une réponse peut prendre du temps. La complexité de votre question a également un impact. La langue n’a pas d’importance : français, néerlandais, anglais, le modèle prend en charge de nombreuses langues.
Vous pouvez demander à Ollama de vous aider à résumer un projet. La réponse suivra assez rapidement. Lorsque vous envoyez le résumé, le véritable travail commence seulement et cela peut parfois prendre jusqu’à une demi-heure avant d’obtenir la réponse.
Ollama et la version locale de ChatGPT ont aussi leurs limites. Vous ne pouvez pas télécharger des fichiers pour les analyser ou générer des images. Pour cela, vous devez utiliser la version en ligne de ChatGPT.
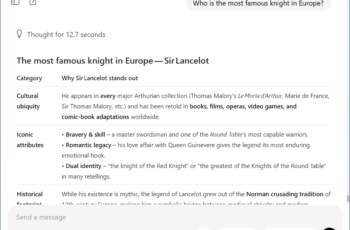
Vous devez parfois attendre des minutes pour une réponse ? Maintenant vous réalisez la puissance de ChatGPT dans le cloud avec des millions de GPU « s qui sont prêts pour vous. En exécutant un modèle localement, vous prenez conscience de la puissance de calcul nécessaire pour les modèles de langage. Et l’énergie nécessaire pour alimenter (et refroidir) les GPU » s. Utilisez donc la version en ligne de ChatGPT de manière judicieuse.
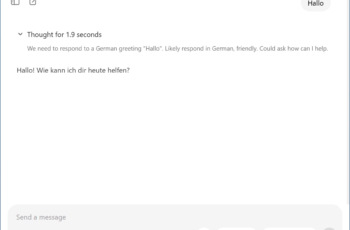
Détail intéressant : le modèle local de ChatGPT indique aussi son raisonnement. Vous pouvez ainsi littéralement suivre comment il veut aborder une question et parfois ajoute une note critique lorsque vous approfondissez les détails ou les faits.
Entre-temps, OpenAI se prépare pour le lancement de GPT-5. GitHub a déjà divulgué les premières données.