
Cloudflare sort un nouvel outil pour empêcher les robots d’indexation d’accéder aux sites web. La méthode est plus robuste que la méthode robot.txt.
En cette époque d’IA générative, il est plus important que jamais de protéger son contenu. Aujourd’hui, l’internet déborde de robots d’indexation à la recherche de données pour former des modèles. Cloudflare annonce une nouvelle technique qui permet aux administrateurs de sites web d’empêcher plus facilement les robots d’exploration de pénétrer sur le web. Cet outil repose sur un système d’« empreintes digitales ».
Les robots d’indexation font désormais partie intégrante du trafic internet. Cloudflare estime qu’environ 40 % du million de sites qu’il gère ont déjà été visités par un robot d’indexation. Sur les dix premiers sites, c’est même quatre-vingts pour cent. Ce sont des « araignées » numériques qui parcourent les sites web sans être détectées et qui collectent des données pour former des modèles d’intelligence artificielle.
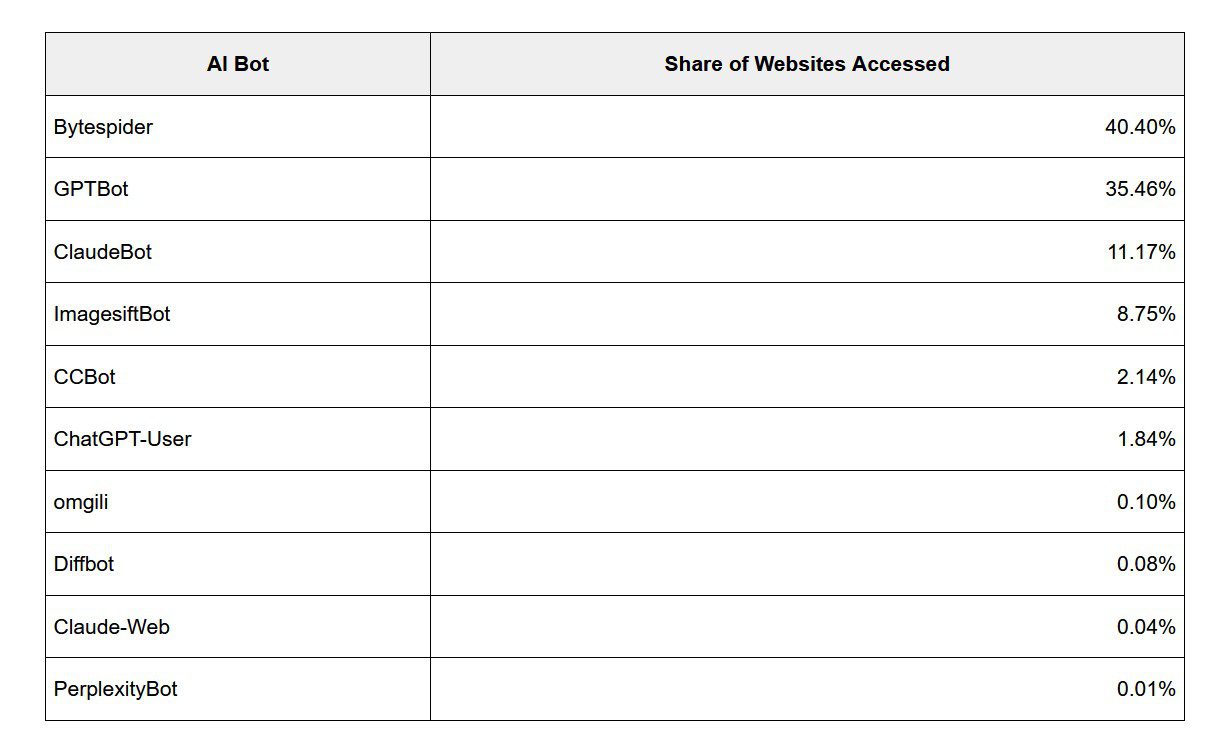
Selon Cloudflare, le robot d’indexation le plus actif est Bytespider, qui appartient à Bytedance, la société mère de TikTok. Il a déjà été détecté sur 40 % des sites web. Mais le GPTBot d’OpenAI est également très présent, avec 35 % des sites.
Robots.txt
Il existe déjà une astuce pour rendre la tâche plus difficile aux robots d’indexation. En injectant le fichier robot.txt dans le répertoire der son site web, on bloque l’accès aux robots d’indexation. Notons qu’OpenAI et Google eux-mêmes recommandent cette astuce aux administrateurs de sites web qui ne peuvent pas être visités par leurs robots d’indexation.
Cloudflare explique toutefois que Robot.txt ne fonctionne pas à toute épreuve. Les administrateurs de sites web ne le mettent pas toujours en œuvre ou ne l’appliquent qu’à un nombre limité de robots d’indexation. Et les développeurs de robots d’indexation ne sont pas toujours très corrects non plus. En « déguisant » un robot d’indexation en visiteur légitime d’un site web, on peut facilement le contourner.
Empreinte digitale
Cloudlfare a développé un nouveau système contre ces robots d’indexation, en réduisant les points faibles par lesquels ils peuvent passer. L’outil vérifie l’« empreinte digitale » de l’identité qui envoie une requête au site web. Ironiquement, Cloudflare utilise l’apprentissage automatique pour déterminer si l’empreinte correspond ou non à un robot d’indexation.
L’outil est disponible pour tous les clients de Cloudflare et peut être activé d’un simple clic dans le tableau de bord de gestion. Il y aura un nouveau bouton Block AI Scrapers and Crawlers dans le menu de sécurité.